днк 576.3/.7
WHY ARE THERE FOUR LETTERS
IN DNA CODE?
A. A. Arzamastsev
Department of Physics and
Mathematics, Tambov State University
Key Words and Phrases: DNA code; four-letters code; number
of letters;
information ingredient minimum.
Abstract: The aminoacid alphabet having 21
characters (twenty of which are aminoacides and one
representing stopsignal) is explained by the fact
that the DNA code has four letters. There is no explanation so far why DNA code
has four letters. We report here that the DNA four- letters code that takes
place in information strands of DNA is optimal from the standpoint of cell
information ingredient minimum. Such optimality may be achieved for simple DNA
only. These facts may serve as an indirect evidence, that it is these DNA that
were the "design" object at one of the early stages of biological
evolution.
Introduction
As a result of fundamental
researches made by Avery, Watson and Crick in a short period of time
(1944-1966) the nature and mechanisms of genetical
information transfer were discovered [1-5]. This information is known to be
written in DNA strands as a sequence of nucleotides. It is read by means of
messenger and transfer RNA by triplets (kodones),
information being further translated through ribosomes
into appropriate aminoacids. The aminoacid
alphabet having 21 characters (twenty of which are aminoacides
and one representing stopsignal) is explained by the
fact that the DNA code has four letters [5,6]. There
is no explanation so far why DNA code has four letters. We report here that the
DNA four- letters code that takes place in information strands of DNA is
optimal from the standpoint of cell information ingredient minimum. Such
optimality may be achieved for simple DNA only. These facts may serve as an
indirect evidence, that it is these DNA that were the "design" object
at one of the early stages of biological evolution.
Basic concepts
It is evident that in most
cases of "designing" various objects Nature followed certain
principles of optimality which correspond to maximum or minimum of some
objective function. To investigate Nature means to find these objective
functions. Hence, to understand why the primary biological code is a
four-letters code practically means to find such an objective function which achieves its maximum or minimum provided the
number of letters is four.
While solving the problem of DNA code optimality one should bear in mind its
primary alphabet, i.e. four- letters alphabet of DNA, rather than 21- letters aminoacid alphabet which is the result of a translation.
When it is necessary to choose the way of recording information one has to
decide either in favour of a small or a large number
of letters in the alphabet (n). The first alternative simplifies the decoding
information machine but leads to lengthy information strands. The latter, on
the contrary, shortens the length of a strand but complicates the information
machine. The total result of such optimization (compromise) is obtaining
minimal value of one of the parameters of information ingredient (for example,
volume). This ingredient is the sum of the corresponding parameters of the
decoding machine and the programme itself.
Nature might have followed similar principles creating "information
ingredient" of simple biological objects at one of the early stages of
biological evolution. For the first time this concept was described [7].
Results and discussion
In
all probability Nature tends to decrease the part of the cell information
ingredient. Thus the volume of the cell remaining the same, the greater part of
the cell can be utilized for useful purposes. Indeed from the standpoint of the
Present, information media has not any special meaning, it is just used to
transfer information from the Present to Future. This statement is well
illustrated by Table 1, which shows that the increase of organisms
complexity results in the decrease of the part of cells information media
[8-10].
Table 1
The information ingredient value for various bioobjects
|
Bioobject |
Part
of total mass of a cell, % |
|
|
|
DNA |
RNA |
|
Viruses |
5-64 |
5-32 |
|
Bacterial cell |
1 |
6 |
|
Mammalian cell |
0.25 |
1.1 |
To prove this let us suppose that a cell has to code a number of various
possibilities (N) into information strand. If for this purpose the cell chooses
n- letters alphabet, then the length of the information strand (the number of
letters in the programme) will be calculated
according to the equation:
|
L = logn(N) = ln(N)/ln(n) |
(1) |
If the programme
has a cylindrical form, the length of one letter being lc
and radius r, which are characteristic of the secondary DNA structure,
then the whole information strand will have the following volume:
|
Vi
= |
(2) |
It is also evident that the
increase of n results in the increase of the complexity of the decoding
information machine and therefore in the increase of its volume, i.e.:
|
Vm = kn |
(3) |
where k- is a certain constant of
the proportionality. So, the total volume of a cell information ingredient is:
|
V = Vi
+ Vm = |
(4) |
where C- is a certain constant
which is a total volume of all the elements not depending on n (for
example, the volume of protein factors, membrane structures, etc.).
Fig.1 (a,b) shows the
qualitative dependence of Vi and Vm
on n (equation (4)). One can see that dependence Vi(n)
is decreasing, while Vm(n)
is increasing, so that the summarized dependence V(n) is unimodal having its minimum (fig.1 c).
To show the minimum of the summarized volume of cell information ingredient
takes place at n=4, we identify parameters and coefficients of equations
(1)-(4) on the basis of known data, so that equation (4) would be the function
of one variable (n) only. From the secondary DNA structure (the radius
of the cylinder approximates 1 nm and the length of one nucleotide amounts to
0.34 nm) it follows that lc=0.34.10-9
m and r=10-9 m [6,11]. Since the
information machine of a cell is the ribosome, the linear dimension of which
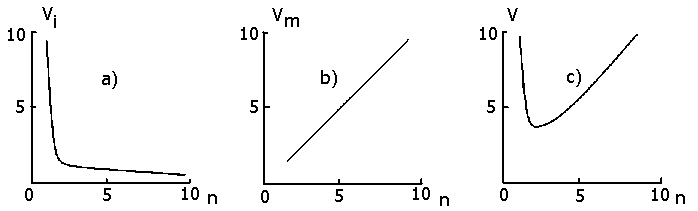
Fig.1. Dependences of the volumes Vi (a), Vm (b) and the total volume of cell
information ingredient V (c) (according to ordinate axis), on the number
of letters in an alphabet- n (according to abscice
axis) when k=1 and r2lcln(N)=1
are fixed.
approximates 1.8.10-8 m and its
volume is 3.10-24 m3 [8,11] we find for n=4
that k=V/n=0.75.10-24. Then
|
V(n) = |
|
The function presented by
equation (5) has its minimum if the expression in square brackets is minimal. Let
us find n at which the value of the expression is minimal. For this purpose we
determine the derivative dV/dn and compare it
to zero.
|
dV/dn
= -10-3.ln(N)/{n.ln2(n)}
+ 0.75 = 0 |
(6) |
The latter equation may be
solved by numerical methods only. The result of computer calculation will be
n=4 if ln(N)= 5765.4.
Hence it is possible that designing the molecular mechanism of information
transfer, Nature might have attempted to do it in the most compact form,
solving in this way the problem of monodimensional
optimization.
It is worth discussing here the value of ln(n). It should be noted that N is a
summarized number of possibilities coded in the genome. It is easy to show that
the derived value of ln(n) corresponds to the length of the DNA strand which
approximates 4200 nucleotide pairs (letters). The programme
of such a length is characteristic of the simplest organisms, mitochondrial DNA
and some viruses.
Table 2 presents certain values of information strand length known from modern
biology, ln(N), and optimal number of
letters in the alphabet (found from equation (6)), characteristic of various
living organisms. The table shows that the optimal number of letters in the
alphabet (n=4) corresponds only to the simplest forms of life and DNA. For
more complex organisms the value of n is one or several orders greater.
If the above mentioned arguments are correct, it means that the
"design" situation of DNA code by Nature is surprisingly analogous to
that of designing computers by a human being. If the first computers had been
constructed nowadays, the binary notation system might not have been used. It
was chosen at the early stage in order to simplify as much as possible the
design of the decoding machine. It is too late to correct this mistake now.
Probably an identical "miscalculation" was made by Nature, while designing
living organisms. In any case, the analogy is evident.
To be more illustrative Fig.2 shows the dependence analogous to that described
in Fig.1, however built in accordance with the real parameters and coefficients
obtained in the course of calculations. This figure clearly shows that the
values of the summarized volume V corresponding to the values of n
equal to 3,4 and 5 are located approximately
Table 2
Optimal number of letters in the alphabet for various living organisms
|
Living organisms |
Length
of DNA strand, bases or base pairs |
Ln(N) |
O
Optimal number of letters in the alphabet |
|
Homo |
3.109 |
4.2.109 |
47780 |
|
Strongylocentrotus purpuratus |
8.108 |
1.1.109 |
15828 |
|
Drosophila melanogaster |
1.6.108 |
2.2.108 |
4242 |
|
Saccharomyces cerevisiae |
1.35.107 |
1.9.107 |
607 |
|
Escherichia coli |
4.106 |
5.6.106 |
245 |
|
Bacteriophage |
48502 |
6.7.104 |
13 |
|
Bacterial virus |
5386 |
7.5.103 |
4 |
|
Hypothetical
bioobject with base strand length equal to 4159 |
4159 |
5.8.103 |
4 |
|
|
|
on the
same level. It means that the sensibility of V to n at n
equal to 3 - 5 is extremely low. That is why Nature might have chosen any
value of n from this domain. The choice of Nature in favour
of n=4 permits to get an additional degree of freedom, slightly
changing the length of DNA strand without influencing the total optimality. Thus,
at parameters values referred to in this article, the minimal values of
equations (4) and (5) are obtained at n=4 (provided that n- is
an integer), if the length of DNA strand varies within a wide range, from
3110 up to 5400 bases or base pairs. Thus, we have demonstrated that four- letters code which takes place in information DNA strands is optimal from the standpoint of the summarized volume minimum of the cell information ingredient. This optimality is relevant for the simplest DNA only. |
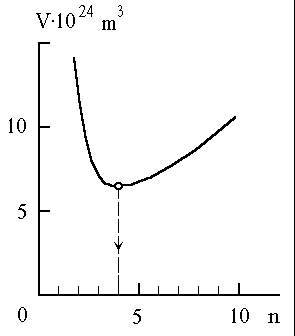
This indirectly proves that
the simplest DNA (rather than more complex ones) were
the object of "design" at one of the early stages of biological
evolution.
References
- Avery O.T., MacLeod C.M. & MacCarty M. J. Exp. Med. 79,137158 (1944).
- Watson J.D. & Crick F.H.C. Nature. 171, 737-738 (1953).
- Watson J.D. & Crick F.H.C. Nature. 171, 964-967 (1953).
- Crick F.H.C. Sci.
Am. 215, 55-62 (1966).
- Watson J.D., Tooze
J. & Kurtz D.T. Recombinant DNA. Scientific American Books.
Distributed by W.H. Freeman and Company,
- Arzamastsev A.A. Zhurnal
Obshchei Biologii. 56,
405-410 (1995) in Russian and English translation.
- Alberts B., Bray D., Lewis J., Raff M., Roberts K. & Watson J.D. Molecular Biology of the Cell. Garland Publishing, Inc. New York, London, (1983).
- Sengbusch P. Molekular
- und Zellbiologie.
- Musil J., Novakova O., Kunz K. Biochemistry in schematic perspective. Czechoslovak Medical Press, Prague, (1980).
- Volkenstein M.V. Biophysika . Nauka,
ACKNOWLEDGEMENTS. I thank A.V. Troizki
(